
Die Stimme ist das wichtigste Instrument, wenn es darum geht, unsere Gedanken und Ideen zu vermitteln. Aber was passiert, wenn wir Schwierigkeiten haben, unsere Worte klar auszusprechen oder unseren Text in eine ansprechende Stimme zu verwandeln? Hier kommen Sprachgeneratoren ins Spiel! Mit ihrer bahnbrechenden Text-to-Speech-Technologie können sie nicht nur Menschen mit Lernschwierigkeiten unterstützen, sondern auch Marketingunternehmen und Filmemacher bei der Erstellung von qualitativ hochwertigen Voice-over-Komponenten helfen. Und das Beste daran? Diese Tools eignen sich sogar perfekt für die Vertonung von Lernvideos! In diesem Blogpost erfahren Sie alles über die faszinierende Welt der Sprachgeneratoren.
Was sind Sprachgeneratoren oder TTS?
Ein Sprachgenerator oder TTS ist ein Gerät oder eine Anwendung, die Text in menschenähnliche Sprache umwandelt. TTS wird in einer Vielzahl von Anwendungen eingesetzt, z. B. in Hörbüchern, E-Learning und sprachgesteuerten Geräten.
Die neueste Entwicklung bei TTS ist der Einsatz von künstlicher Intelligenz (KI). KI-gestützte TTS-Systeme sind in der Lage, natürlicher klingende Sprache zu erzeugen als herkömmliche TTS-Systeme. Das liegt daran, dass KI-Systeme in der Lage sind, die Nuancen der menschlichen Sprache wie Intonation, Rhythmus und Betonung zu lernen.
KI-gestützte TTS-Systeme befinden sich noch in der Entwicklung, aber sie haben das Potenzial, die Art und Weise, wie wir mit Technologie interagieren, zu revolutionieren. KI-gestützte TTS-Systeme könnten zum Beispiel eingesetzt werden, um Hörbücher und E-Learning-Erlebnisse noch intensiver zu gestalten. Sie könnten auch verwendet werden, um sprachgesteuerte Geräte zu entwickeln, die natürlicher und intuitiver zu bedienen sind.
Hier sind einige der neuesten Entwicklungen im Bereich KI-gestütztes TTS:
- Neuronale TTS: Neuronale TTS-Systeme verwenden neuronale Netze, um Sprache zu erzeugen. Neuronale Netze sind eine Art von maschinellen Lernalgorithmen, die komplexe Muster aus Daten lernen können. Dadurch eignen sie sich besonders gut für Aufgaben wie die Erzeugung natürlich klingender Sprache.
- End-to-End-TTS: End-to-End-TTS-Systeme wandeln Text direkt in Sprache um, ohne Zwischenschritte zu benötigen. Das macht sie effizienter und kann zu einer besseren Sprachqualität führen.
- Mehrsprachige TTS: Mehrsprachige TTS-Systeme können Sprache in mehreren Sprachen erzeugen. Das ist nützlich für Anwendungen wie Hörbücher und E-Learning, die oft in mehrere Sprachen übersetzt werden.
KI-gestütztes TTS ist ein sich schnell entwickelnder Bereich mit dem Potenzial, die Art und Weise, wie wir mit Technologie interagieren, zu verändern. Wenn sich die KI-gestützten TTS-Systeme weiter verbessern, werden sie in einer Vielzahl von Anwendungen immer häufiger eingesetzt werden.
Die besten AI-Stimmengeneratoren, die wir bisher gefunden haben:
1. Play.ht
Mit Stimmen von Amazon Polly, Google WaveNet, IBM Watson und Microsoft Azure in über 60 Sprachen hat sich play.ht zu einem der Spitzenreiter der TTS-Branche entwickelt. Abonnenten des Dienstes, der ab $14.25 im Monat erhältlich ist, können .wav und .mp3- Audio-Dateien generieren. Wort für Wort können Sie bei Bedarf die Aussprache, Tonhöhe und Pausen definieren sowie die Geschwindigkeit festlegen.
Verfügbar sind dort auch die 90 WaveNet-Stimmen von Google, bei der kaum noch ein Unterschied zur menschlichen Sprache festzustellen ist.
Außerdem überzeugt play.tv mit zahlreichen Integrationen. Neben einer API bietet der Dienst ein WordPress-Plugin, eine Browser-Erweiterung, ein JS Code Snippet und Audio-Widgets an.
Die generierten Dateien lassen sich als Podcast hosten, indem ein RSS feed generiert wird, der um die relevanten Informationen wie Copyright, Autor und Beschreibung ergänzt werden.
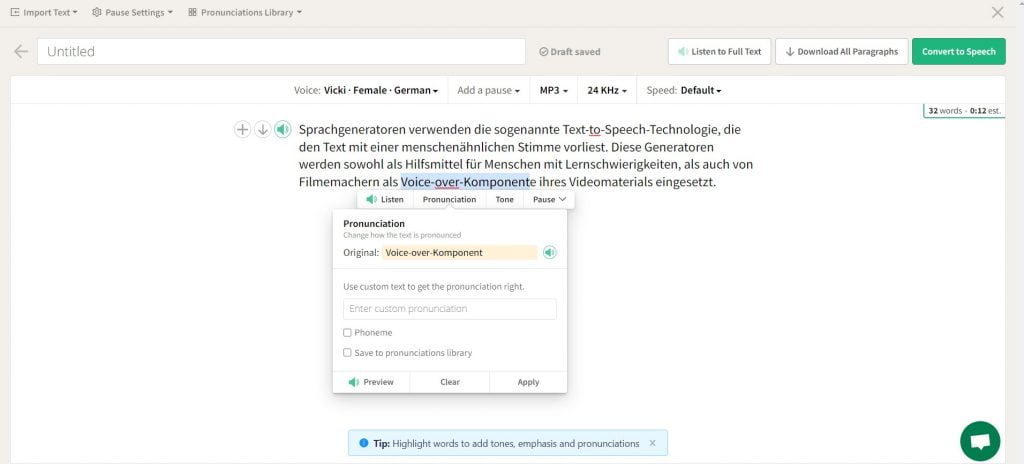
2. Spik.ai
Mit Spik.ai können Benutzer Eingaben in Form von einfachem Text oder Speech Synthesis Markup Language (SSML) machen. Die Benutzer können ohne Anmeldung Audiodateien aus Text mit bis zu 300 Zeichen erzeugen. Diese Grenze wird für registrierte Benutzer auf 1.000 Zeichen erhöht. Die Software verfügt über eine Reihe von Stimmen und Akzenten. Leider lässt sich die Geschwindigkeit des Audios nicht steuern. Außerdem beschränken sich die Sprachen auf Englisch, Spanisch, Französisch, Deutsch, Arabisch und Chinesisch.
Außerdem können Audio-Dateien transkribiert werden.
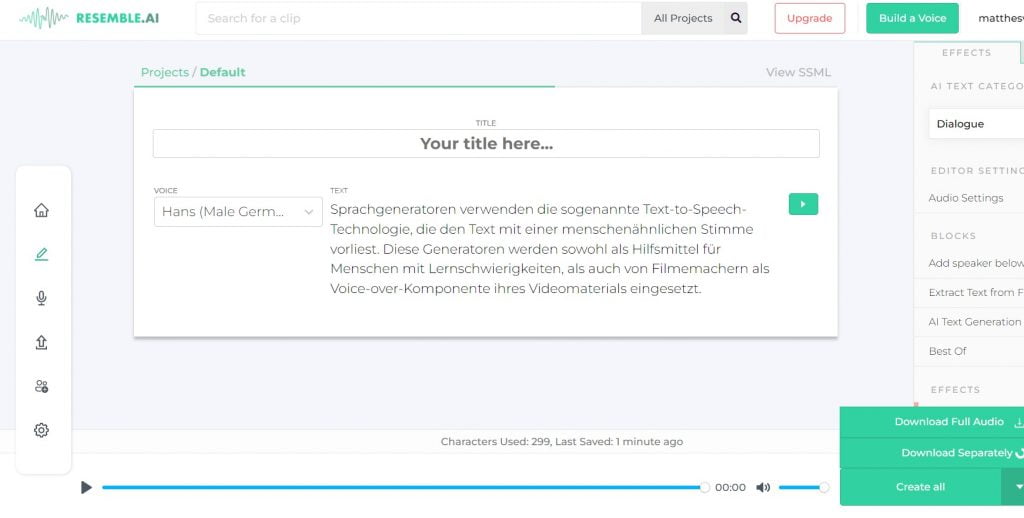
3. Resemble.ai
Mehr als als eine Million Audioclips pro Monat werden auf der Resemble-Plattform generiert! Dieses Tool bietet 54.705 Stimmen an, mit denen Text in Sprache umgewandelt werden kann. Dabei kommen alle möglichen Zwecke in Frage: Zum Beispiel Werbedialoge, Markenstimmen für Assistenten und IVR-Agenten. Stimmen können dabei auch verängstigt oder wütend klingen. Derzeit nur auf Englisch, aber dennoch interessant: Sie können ihre eigene Stimme klonen. Über ein geführten Dialog müssen Sie dafür einige Sätze vorlesen, aus der Ihre Stimme mit Deepfake AI generiert wird.
Die Text zu Sprache-Plattform kann kostenlos getestet werden – das günstigste Abo kostet $30 im Monat.
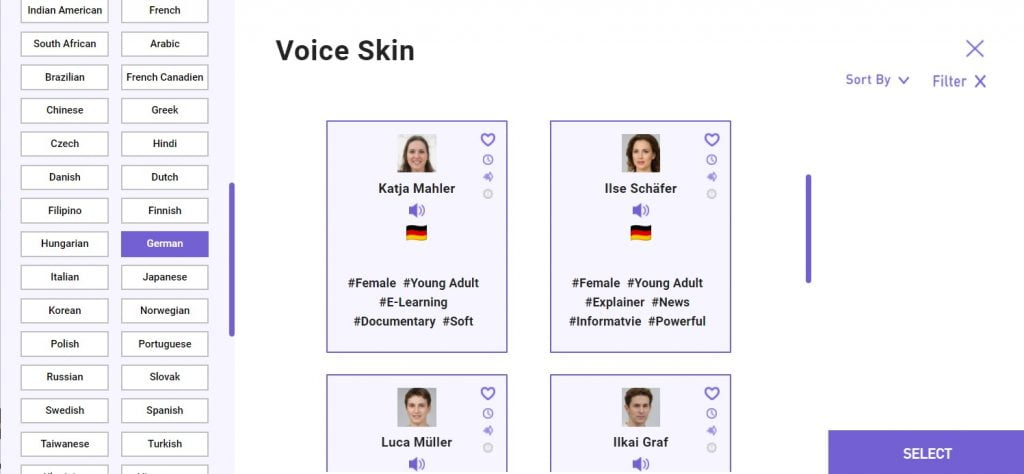
4. Lovo – Love Your Voice
Lovo bietet eine kostenlose Version für den persönlichen Gebrauch an, mit unbegrenzten Konvertierungen, Wiedergabe und Teilen an. Allerdings ist der Download des Audio auf drei Dateien pro Monat begrenzt und nur für die persönliche Nutzung bestimmt.
Ab einem Preis von $34.99 im Monat können Sie die Dateien auch für kommerzielle Zwecke verwenden und ihr Hintergrundmusik hinzufügen.
5. WellSaid Labs
Vom menschlichen Original kaum zu unterscheiden, hört sich der Text-To-Speech von WellSaid Labs sehr natürlich an. Das ganze hat allerdings seinen Preis: Ab $49 im Monat ist das günstigste Abo zu haben; damit lassen sich 250 Audio-Dateien erzeugen und 5 Projekte anlegen. Derzeit ist das Text zu Sprache-Tool jedoch nur auf Englisch verfügbar.
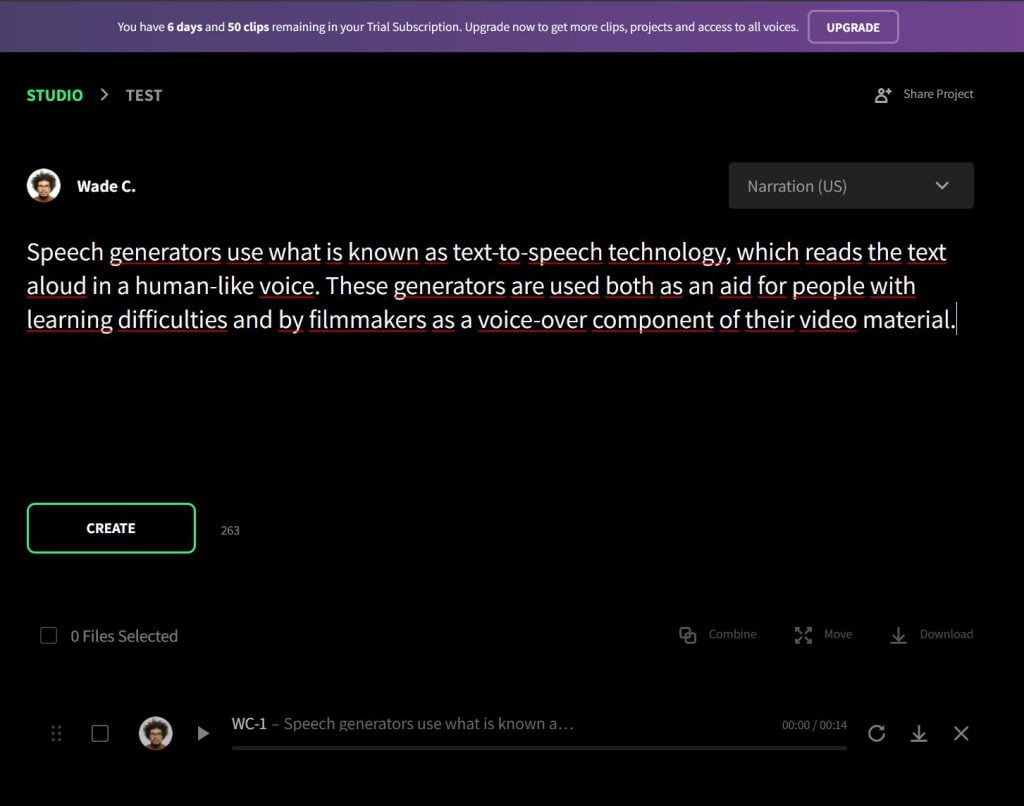
Immerhin: Mit dem einwöchigen Testzugang können Neugierige testen, wie sich die insgesamt 37 Voice-Avatare anhören.
6. Speechify
Speechify ist eine Text-to-Speech-Anwendung, die künstliche Intelligenz verwendet, um verschiedene Arten von Texten wie Bücher, PDFs und Webseiten in hörbare Sprache umzuwandeln. Sie unterstützt mehrere Sprachen mit anpassbaren Sprachoptionen, Geschwindigkeit und Ton. Die Anwendung ist besonders nützlich für Menschen mit Leseschwierigkeiten, Studierende mit hohem Lernpensum oder Menschen, die effizienter lesen möchten. Speechify integriert sich in Pocket, Instapaper und Safari, so dass Benutzer nahtlos zwischen den Geräten wechseln können, und bietet Funktionen zur Barrierefreiheit, um die Benutzerfreundlichkeit für alle Benutzer zu gewährleisten. Die App bietet eine begrenzte kostenlose Demo und Premium-Preise beginnen bei $11,58 / Monat (jährlich abgerechnet).
7. Elai.io
Nicht nur Audiodateien lassen sich mit TTS-Programmen erzeugen. Die Technologie ermöglicht auch das Generieren von Videos, bei der der Text von einem Avatar vorgelesen wird. Bei Elai.io können Sie Powerpoint-Präsentationen, PDF-Dateien oder Google Slides hochladen, mit einem Text versehen und daraus ein Video generieren.
In Form von Slides fügen Sie Hintergrundbilder hinzu und ergänzen diese um Elemente wie Formen, Texte und Bilder. Aus Ihrer Slideshow wird dann ein Video generiert. Ideal, wenn Sie Präsentationen vertonen möchten oder ein Marketingvideo in mehreren Sprachen brauchen.
8. Murfai.ai
Murfai.ai ist ein beliebter KI-Sprachgenerator, der realistische menschliche Stimmen mit Intonation, Aussprache und Emotionen erzeugt. Benutzer können Stimmen in verschiedenen Sprachen wie Englisch, Spanisch, Französisch, Deutsch, Italienisch, Portugiesisch, Chinesisch und vielen anderen erzeugen und zwischen verschiedenen Akzenten wählen. Anpassungsfunktionen wie Sprechgeschwindigkeit, Tonhöhe und Lautstärke ermöglichen eine individuelle Anpassung an die Bedürfnisse des Nutzers.Murfai.ai bietet ein Pay-per-Use-Modell, bei dem nur für die Anzahl der zu konvertierenden Zeichen bezahlt werden muss. Es gibt eine kostenlose Testversion mit 5.000 Zeichen, mit der man den Dienst ausprobieren kann, bevor man sich für einen Plan entscheidet. Die Preise beginnen bei $29 pro Monat oder $19 pro Monat bei jährlicher Abrechnung.
9. Elevenlabs
In den letzten Jahren hat die Sprachtechnologie enorme Fortschritte gemacht. Die Firma ElevenLabs hat kürzlich ein neues Sprachsynthesemodell namens Eleven Multilingual v1 auf den Markt gebracht, das sieben zusätzliche Sprachen unterstützt. Dazu gehören Französisch, Deutsch, Hindi, Italienisch, Polnisch, Portugiesisch und Spanisch. Eine besonders interessante Funktion von Eleven Multilingual v1 ist die Möglichkeit, erstmals eine Stimme in Deutsch zu klonen. Das dafür erforderliche Abo erhältst Du ab $5 im Monat.
Fazit der Tools für Text-Zu-Sprache
Mit diesen Tools können Sie den Geld- und Zeitaufwand für die Erstellung von Voiceovers erheblich reduzieren. Die Anwendungsmöglichkeiten sind schier unendlich: Sei es das Vorlesen eines Blog-Beitrags oder das Vertonen eines Videos. Die Sprachsynthese wird dabei immer lebensechter, wobei die Entwicklung in Englisch bereits am weitesten vorangeschritten ist.